Hate speech detection
Early this year the nonprofit Open Knowledge Finland approached us with their request to get pro bono data science help in prototyping and testing a machine learning hate speech detection system during our municipal elections here in Finland.

(Foreword by Teemu Turunen, Corporate Hippie of Futurice). The fast paced and fragmented online discussion is changing the world and not always to the better. Media is struggling with moderation demands and major news sites are closing down commenting on their articles, because they are being used to drive an unrelated political agenda, or just for trolling. Moderation practise cannot rely on humans anymore, because a single person can easily generate copious amounts of content, and moderation needs to be done with care. It’s simply much more time consuming than cut and pasting your hate or ads all across the internet. Anonymity adds to the problem, as it seems to bring out the worst in people.
The solution would monitor public communications of the candidates in social media and attempt to flag those that contain hate speech, as it is defined by the European Commission and Ethics Journalism Network in https://www.article19.org/data/files/medialibrary/38231/'Hate-Speech'-Explained---A-Toolkit-(2015-Edition).pdf.
The non-discrimination ombudsman (government official appointed by our government to oversee such matters) would review the results. There are also university research groups involved. This would be an experiment, not something that would remain in use.
After some discussion and head scratching and staring into the night we agreed to take the pro bono project.
A tedious and time consuming repetitive task is a good candidate for machine learning, even if the task is very challenging. Moderation by algorithms is already done, just not transparently. An example? Perspective API by Jigsaw (formerly Google Ideas) uses machine learning models to score the perceived impact a comment might have on a conversation. The corporations that run the platforms we broadcast our lives on are not very forthcoming in opening up these AI models. The intelligence agencies of course even less so.
So we feel there’s a need for more open science. This technology will reshape our communication and our world. We all need to better understand its capabilities and limitations.
We understand that automatic online discussion monitoring is a very sensitive topic, but we trust the involved parties – specifically the non-discrimination ombudsman of Finland – to use the technology ethically and in line with the Finnish law.
In this article our Data Scientist Teemu Kinnunen shares what we have done.
Technology
The hate speech detection problem is very challenging. There are virtually unlimited ways how people can express thoughts including also hate speech. Therefore, it is impossible to write rules by hand or a list of hate words, and thus, we crafted a method using machine learning algorithms.
The main goal in the project was to develop a tool that can process messages in social media and highlight the most likely messages containing hate speech for manual inspection. Therefore, we needed to design a process to find potential hate speech messages and to train the hate speech detector during the experiment period. The process we used in the project is described in Fig. 1.
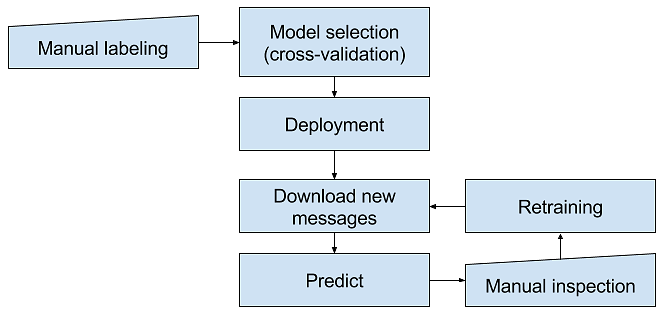 Figure 1: Process diagram for hate speech detection.
Figure 1: Process diagram for hate speech detection.
At first, a manually labeled training set was collected by a University researcher. A subset from a dataset consists of public Facebook discussions from Finnish groups, collected for a University research project HYBRA, as well as another dataset containing messages about populist politicians and minorities from the Suomi24 discussion board. The training set was coded by several coders to confirm agreement of the data (kappa > .7). The training set was used to select a feature extraction and machine learning method and to train a model for hate speech detection. Then we deployed a trained model that was trained with manually labeled training samples. Next, we downloaded social media messages from a previous day and predicted their hate speech scores. We sorted the list of messages based on predicted hate speech scores and send messages and their scores to a manual inspection. After the manual inspection, we got new training samples which we used to retrain the hate speech detection model.
Feature extraction
Bag-of-features
There are many methods to extract features from text. We started with standard Natural Language Processing methods such as stemming and Bag-of-Words (BoW). At first, we stemmed words in the messages using Snowball method in the Natural Language Toolkit library (NLTK). Next, we generated a vocabulary for bag-of-words using the messages in manually labelled training samples. Finally, to extract features for each message, we computed a distribution of different words in the message i.e. how many times each word in the vocabulary exists in the message.Some of the words appear nearly in each message, and therefore, provide less distinctive information. Therefore, we gave different weights for each word based on how often they appear in different messages using the Term Frequency - Inverse Document Frequency weighting (TF-IDF). TF-IDF gives higher importance for the words which are only in few documents (or messages in our case).
Word embeddings
One of the problems in bag-of-features is that it does not have any knowledge about semantics of words. The similarity between two messages is calculated based on how many matching words there are in the messages (and their weights from TF-IDF). Therefore, we tried word embeddings which encodes words that are semantically similar with similar vectors. For example, a distance from an encoding of ‘cat’ to an encoding of ‘dog’ is smaller than a distance from an encoding of ‘cat’ to an encoding of ‘ice-cream ’. There is an excellent tutorial to word embeddings on Tensorflow site https://www.tensorflow.org/tutorials/word2vec for those who wants to learn more.
In practice, we used the fastText (https://github.com/facebookresearch/fastText) library with pre-trained models. With fastText, one can convert words into vector space where semantically similar words tend to appear close by each other. However, we need to have a single vector for each message instead of having varying number of vectors depending on the number of words in a message. Therefore, we used a very simple, yet effective, method: we computed a mean of word encodings.
Machine learning
The task in this project was to detect hate speech, which is a binary classification task. I.e the goal was to classify each sample into a no-hate-speech or a hate-speech class. In addition to the binary classification, we gave a probability score for each message, which we used to sort messages based on how likely they were hate speech.
There are many machine learning algorithms for binary classification task. It is difficult to know which of the methods would perform the best. Therefore, we tested a few of the most popular ones and choose the one that performed the best. We chose to test Naive Bayes, because it has been performing well in spam classification tasks and hate speech detection is similar to that. In addition we chose to test Support Vector Machine (SVM) and Random Forest (RF), because they tend to perform very well in the most challenging tasks.
Experiments and results
There are many methods for feature extraction and machine learning that can be used to detect hate speech. It is not evident which of the methods would work the best. Therefore, we carried out an experiment where we tested different combinations of feature extraction and machine learning methods and evaluated their performance.
To carry out an experiment, we needed to have a set of known sample messages containing hate speech and samples that do not contain hate speech. Aalto researcher Matti Nelimarkka, Juho Pääkkönen, HU researcher Salla-Maaria Laaksonen and Teemu Ropponen (OKFI) labeled manually 1500 samples which were used for training and evaluating models.
1500 known samples is not much for such as challenging problem. Therefore, we used k-Fold cross-validation with 10 splits (k=10). In this case, we can use 90% sample for training and 10% for testing the model. We tested Bag-of-Words (BOW) and FastText (FT) (Word embeddings) feature extraction methods and Gaussian Naive Bayes (GNB), Random Forest (RF) and Support Vector Machines (SVM) machine learning methods. Results of the experiment are shown in Fig. 2.
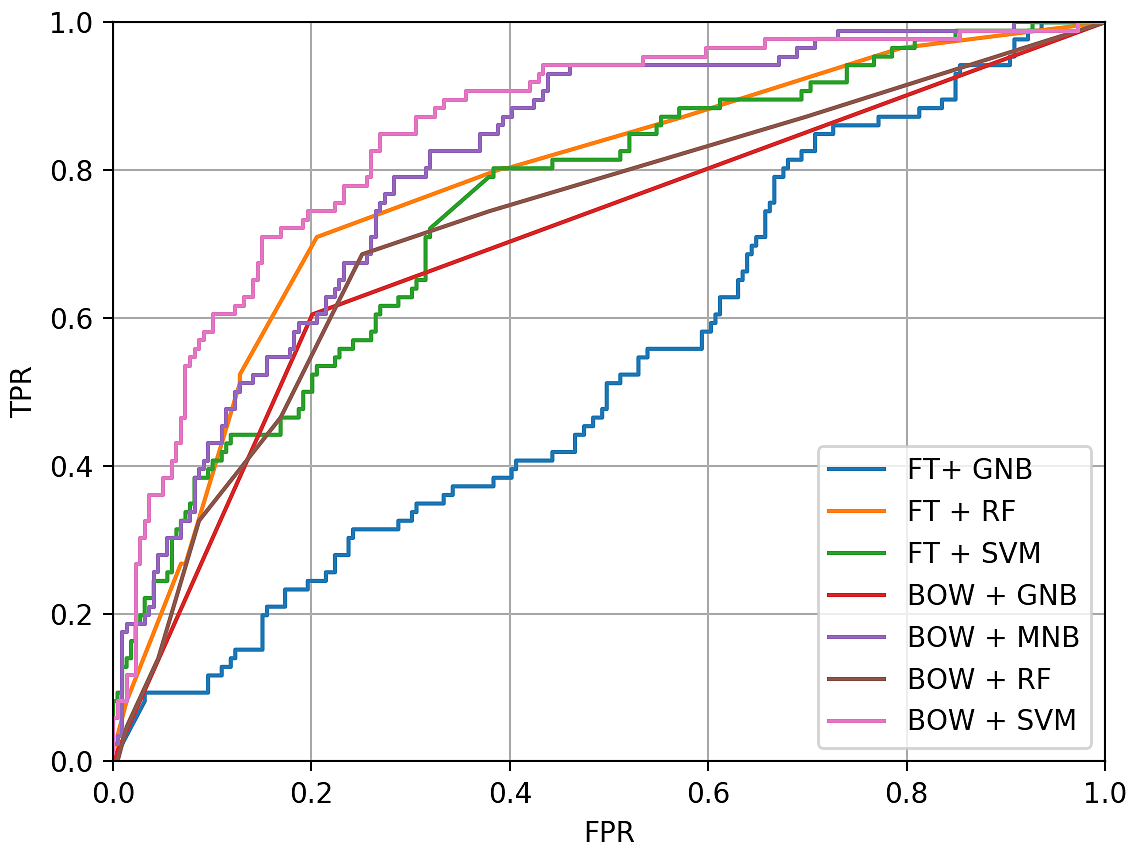 Figure 2: ROC curves for each feature extraction - machine learning method combination. True Positive Rate (TPR) and False Positive Rate (FRP). The FPR axis describes the ratio of mistake (lower is better) and the TPR axis describe the overall success (higher is better). The challenge is to find a balance between TPR and FPR so that TPR is high but FPR is low.
Figure 2: ROC curves for each feature extraction - machine learning method combination. True Positive Rate (TPR) and False Positive Rate (FRP). The FPR axis describes the ratio of mistake (lower is better) and the TPR axis describe the overall success (higher is better). The challenge is to find a balance between TPR and FPR so that TPR is high but FPR is low.
Based on the results presented in Fig. FIGEXP, we chose to use BOW + SVM to detect hate speech. It clearly outperformed other methods and provided the best TPR which was important for us, because we wanted to sort the messages based on how likely they were hate speech.
Model deployment
Based on the experiment, we chose a feature extraction and machine learning method to train a model for hate speech detection. In practice, we used the score of the binary classifier to sort the messages for manual inspection and annotation.
We ran the detector once a day. At first, we downloaded social media messages from a previous day, then predicted hate speech (scored each message) and stored the result in a CSV-file. Next, we converted this CSV-file to Excel for manual inspection. After manual inspection, we got new training samples which were used to retrain the hate speech detection model.
During the field experiment, we found out that the model was able to sort the messages based on the likelihood of containing hate speech. However, the model was originally trained with more biased set of samples, and therefore, it gave rather high scores also for messages not containing hate speech. Therefore, manual inspection was required to make the final decision for the most prominent messages. Further measures concerning these messages were done by the Indiscrimination Ombudsman [who contacted certain parties regarding the findings].
Conclusions
In a few weeks, we built a tool for hate speech detection to assist officials to harvest social media for hate speech. The model was trained with rather few samples for such a difficult problem. Therefore, the performance of the model was not perfect, but it was able to find a few most likely messages containing hate speech among hundreds of messages published each day.
In this work, training -> predicting -> manual inspection -> retraining - iteration loop was necessary, because in the beginning, we had quite limited set of training samples and the style of the hate speech can change rapidly e.g. when something surprising and big happens (A terrorist attack in Sweden happened during the pilot). The speed of the iteration loop defines how efficiently the detector works.
Source codes for the project can be found in GitHub: https://github.com/futurice/spice-hate_speech_detection
The researchers are organizing a workshop to discuss automated detection of hate speech at Association of Internet Researchers annual conference 2017. https://aoir.org/aoir2017/preconworkshop/#LHP
This blog post was written in co-operation with Matti Nelimarkka and Salla-Maaria Laaksonen.
 Teemu KinnunenData Scientist
Teemu KinnunenData Scientist
