The key components for building custom generative AI solutions
When you begin to explore the business potential of AI, the starting point is usually off-the-shelf AI solutions. But sooner or later, you'll start to hit the limitations of these tools. And as everyone else adopts them too, they won't be a source of significant competitive advantage. So developing AI solutions tailored to your specific data, processes, needs & ways of working will inevitably find its way onto the agenda.

There are many different approaches to building custom AI solutions. Custom rarely means ‘building from scratch,’ but stitching together all the latest models, AI & ML services, libraries, and tools to create a tailored solution.
Building demo-level solutions is now rather easy with low or no-code tools. But building production-grade solutions that actually provide real value still takes a lot of work. There’s no one-size-fits-all – the approaches you’ll need depend a lot on the type of data, prompts & goals in each case. Below we’ve collected the key components you need to consider.
Large Language Models (LLMs), Large Multimodal Models (LMMs) & Small Language Models (SLMs)
Generative AI development starts with a model. In 2023, that basically always meant using GPT-3.5 or GPT-4. But now there’s a much more competitive landscape, with a growing collection of high-performance proprietary models like GPT-4o + o1, Claude 3.5 Sonnet & Gemini 1.5. Many of these models are ‘multi-modal’, too – meaning they can work with audio, image, or video data, as well as text. The major proprietary models are now joined by strong open-source models (like Llama-3) and super cheap small language models like Phi-3. So it’s getting crowded out there.
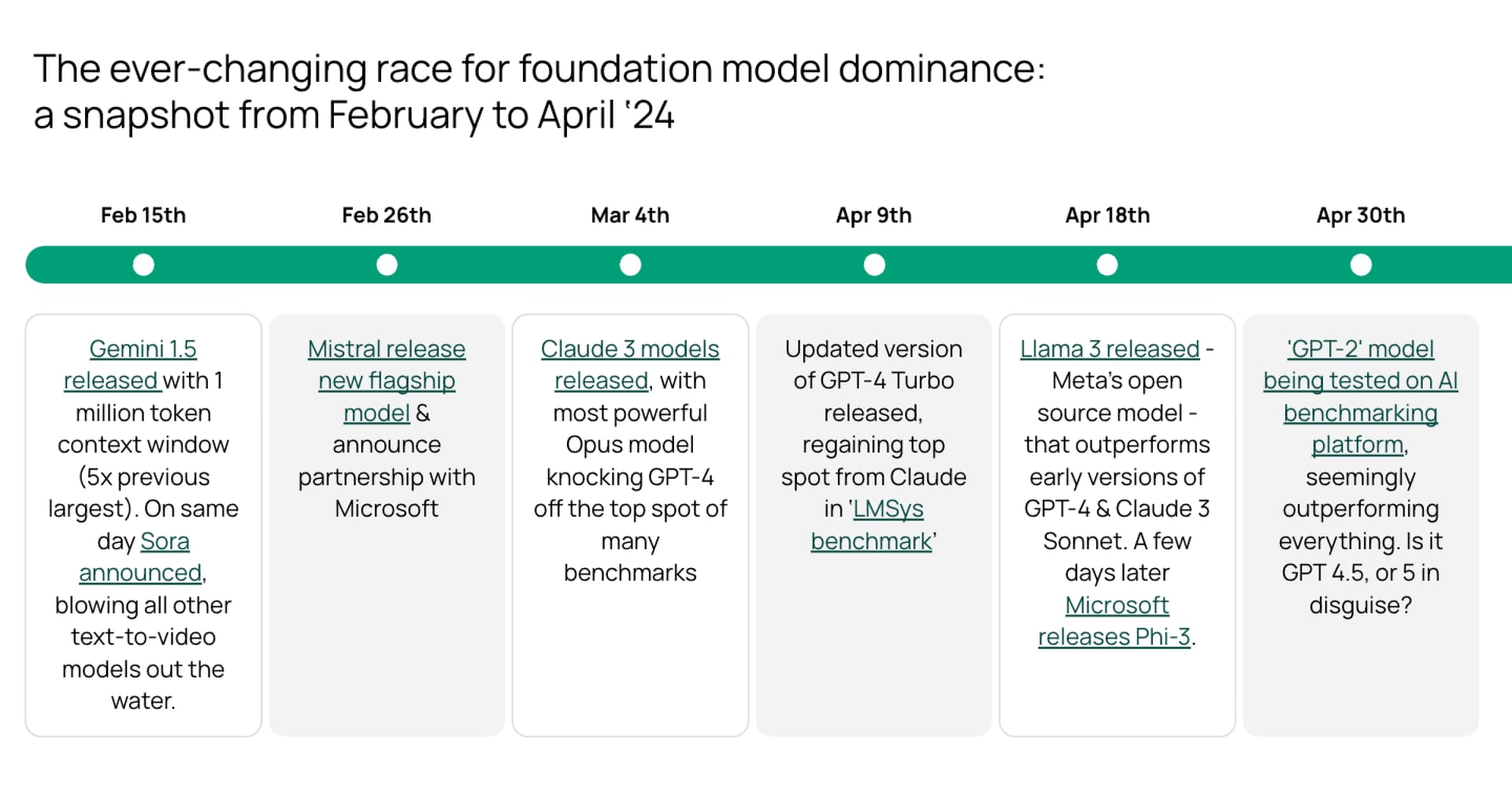
As you can see from the timeline above, things are moving fast! The month after we created this overview, May brought the release of GPT-4o. Then came Claude 3.5 Sonnet, Llama 3 405B, Mistral Large 2, Grok 2, GPT-4o mini, o1 and much more. So you’ll have to follow the ongoing madness yourself with benchmarks like artificial analysis or livebench.
This competition is good for us consumers - with LLMs becoming roughly 1000x cheaper and 10x better in the last 2 years! Different models are evolving to specialise in different tasks, so you should be prepared to use multiple models, even within one solution.
API providers for accessing AI models
To access proprietary models for development, you need to use an API. Azure is currently the leading API provider. They have exclusive access to OpenAI’s models, lots of strong supporting AI & ML services, good developer tools, the best funding program, multiple EU deployment options, and robust data privacy protections.
But other major cloud providers are investing heavily to catch up – for example, Google and AWS have both invested billions in OpenAI rival Anthropic. So the gap to Azure is closing and AWS Bedrock or Google’s Vertex AI are already perfectly viable options in most cases.
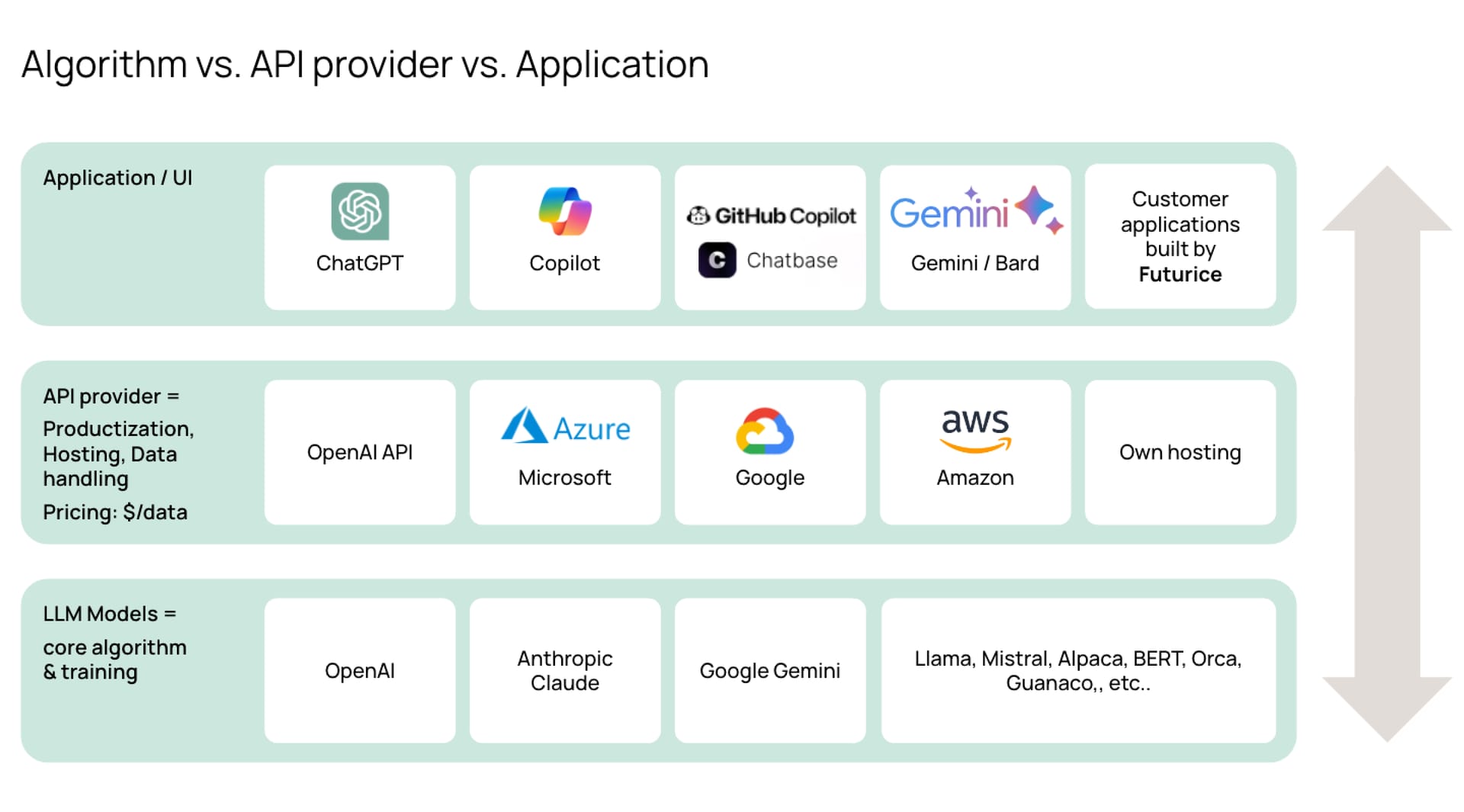
A growing gang of ‘AI-native’ players are also entering the infrastructure market, backed by billions of VC dollars. For example, Groq, Fireworks.ai & together.ai provide innovations that enable significantly faster inference (i.e. model response times), plus easy self-hosting of open-source models. Give Groq a try, it’s rather impressive!
These new players may not be enterprise-ready yet, but the pace of innovation is rather exciting. So, like with the models, you should be prepared to use multiple API providers.
Prompt Engineering
Once you have a development environment set up, the starting point should always be prompt engineering, which is simply instructing the model how to act with your prompt.
This is the easiest way to influence an LLM’s outputs, enabling you to start testing, learning, and iterating in seconds. It’s amazing, really. With an LLM’s base capabilities you can already get them to do so much simply by asking, with no code needed.
Prompt engineering also goes far beyond what you might be used to from chatting with ChatGPT. This is a great guide on the different techniques for dealing with more complex cases and driving better performance. TL;DR, a couple of things are key:
- Asking LLMs to plan, think, and iterate can have a major impact on the quality of their outputs.
- You shouldn’t try to create a complex prompt when dealing with complex tasks. Instead, you should break the task down into a chain of multiple simple prompts.
Retrieval Augmented Generation (RAG), vector databases & hybrid search
RAG is about feeding LLMs with information outside their training data. It’s the de facto way to use an LLM’s language & reasoning capabilities alongside your own knowledge & data.
In practice, you typically turn text data into ‘vector embeddings’ using an embedding model (see benchmarks), then store them in a vector database like Pinecone, Azure AI Search or pgvector (more benchmarks). When a user asks a question from the LLM, the question is turned into a search query of this vector database. The top search results are then passed back to the LLM alongside the original question, with instructions to answer the question with ONLY the context provided.
The vast majority of our gen AI cases have had some element of RAG. Building something that creates real value in production requires a lot more than slapping a chat interface on top of your search. The LLM’s answers can only be as good as the context you give it. So, if your SharePoint or Google Drive search results are shitty (they usually are…), adding an LLM on top will only create polished-looking but still shitty answers.
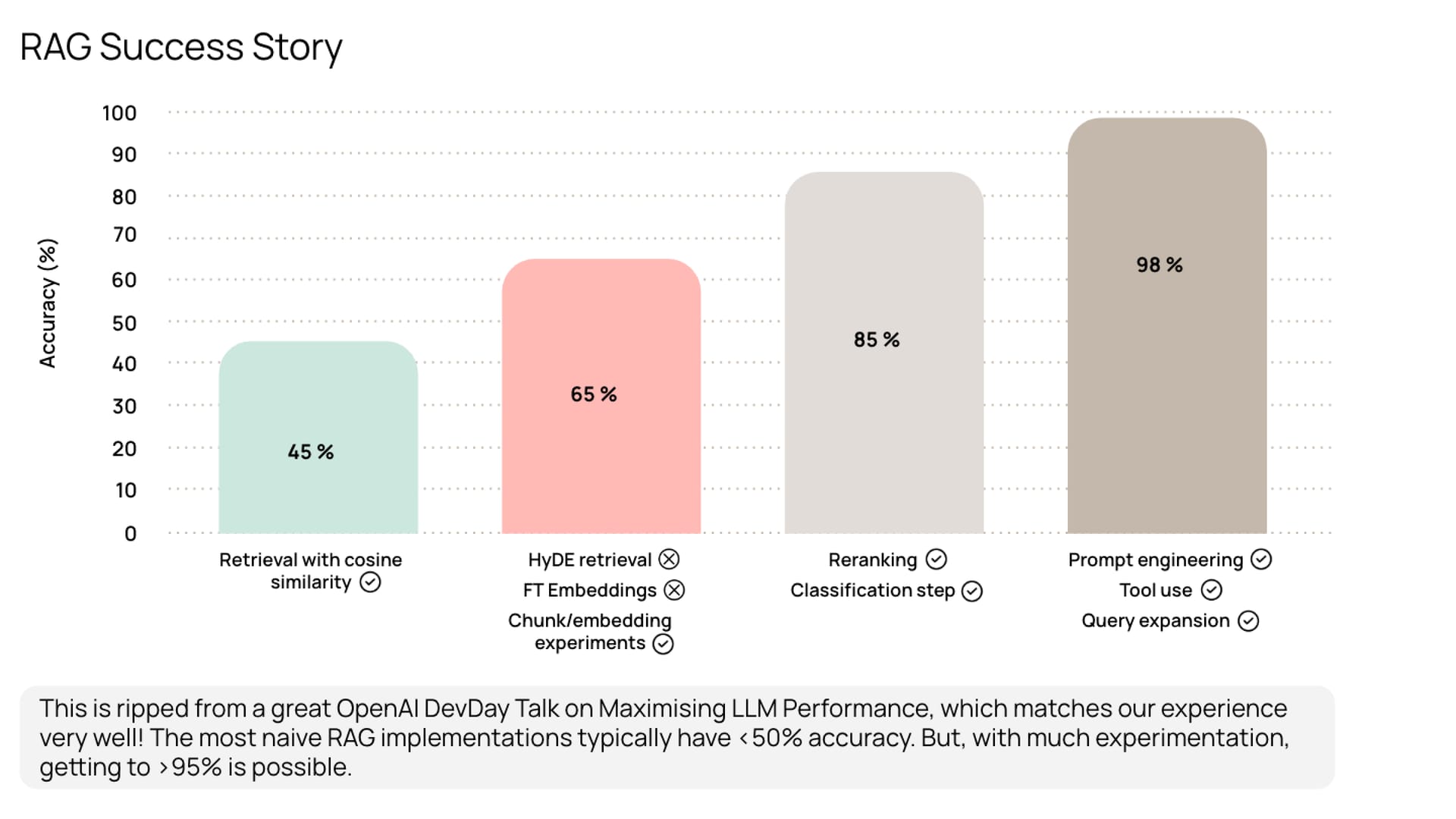
So we’ve had to get familiar with the rather large toolbox of things you can do to improve the context quality: accurate text extraction, different chunking approaches, metadata extraction, classification, search relevancy tuning, reranking, intent recognition, query expansion, prompt engineering, and more.
Leveraging knowledge graphs for higher quality RAG
Knowledge graphs are one emerging approach to creating higher-quality RAG solutions. With graph databases like Neo4J, you can represent the relationships between different pieces of information and combine text and numeric data.
Instead of feeding the LLM with individual chunks of information, you can provide a greater depth of context by showing multiple connected pieces of information together with graphs. This can be really powerful when relationships between data points contain crucial information. For example, legal documents that refer to different clauses and statutes, or recommendation systems where we’re using the behaviour of similar or related users to recommend content/actions.
Graph databases have been around for a while without getting much traction. But LLMs could make them much easier to use. They can help build the graph from raw data by turning unstructured data into graph structure and automating parts of the relationship mapping. They can also effectively turn natural language requests from users into graph database queries.
However, this is still somewhat unexplored territory, with relatively few experts and learning resources available. So, when relationships between data points are important, you may want to try to combine relational and vector databases before jumping straight to graphs.
Fine-tuning generative AI models for specific tasks
Fine-tuning involves training foundational models on a task-specific dataset to emphasise specific behaviours.
It’s used much less frequently than RAG for business use cases and isn’t good for embedding specific knowledge in the LLM, as it doesn’t enable you to control which knowledge the LLM chooses to use for its outputs.
It’s good in cases where you want the model to reliably respond in a certain structured format or tone of voice – for example, capturing a company’s writing style by fine-tuning a model on a bunch of their past content. But its biggest benefit comes in reducing costs at scale, as you may be able to fine-tune a 10-1000x cheaper model to successfully complete a task you first validated with GPT-4.
A growing community is fine-tuning open-source models to perform better in specific domains or tasks. For example, just weeks after the Llama 3 release, thousands of variants were already on huggingface. We’ve not come across one to use in a project yet, but we expect this to be the source of plenty of innovation to come.
Evaluation is key in any digital service. But it’s particularly important with gen AI development, when things are changing fast and there are very few established best practices out there.
In our projects, setting up good quality evaluations has often been rather painful. The challenge is manually building a test dataset to measure the LLM’s responses against. This usually means working with frontline experts to define a set of desired responses for typical prompts and then seeing how well the LLM’s outputs match. In many cases, when the underlying dataset is constantly evolving (e.g., with a knowledgebase assistant), this test set needs to be updated periodically, too. Hence, it takes quite a bit of time.
It’s always worth the pain, though, as trying to optimise by fixing individual cases inevitably turns into a whack-a-mole mess. You’ll fix one thing and break five others.
RAGAS and LlamaIndex are two evaluation frameworks we’ve used, and somewhat more automated testing approaches are starting to emerge.
Using AI agents & tools to automate complex tasks
AI agents are a fast-emerging paradigm for effectively utilising LLMs. Rather than just answering questions, agents have special instructions and tools that enable them to autonomously make plans, take action & iterate until they’ve achieved your goal.
For example, imagine you’re searching the Internet for a specific data point. You could give an AI agent a web-searching tool and instruct them to keep trying different search queries and reviewing the results until they find what you want.
Different task-specific agents can share their outputs and delegate to each other. So you can have a network of specialised agents working together and iterating until they achieve your goal.
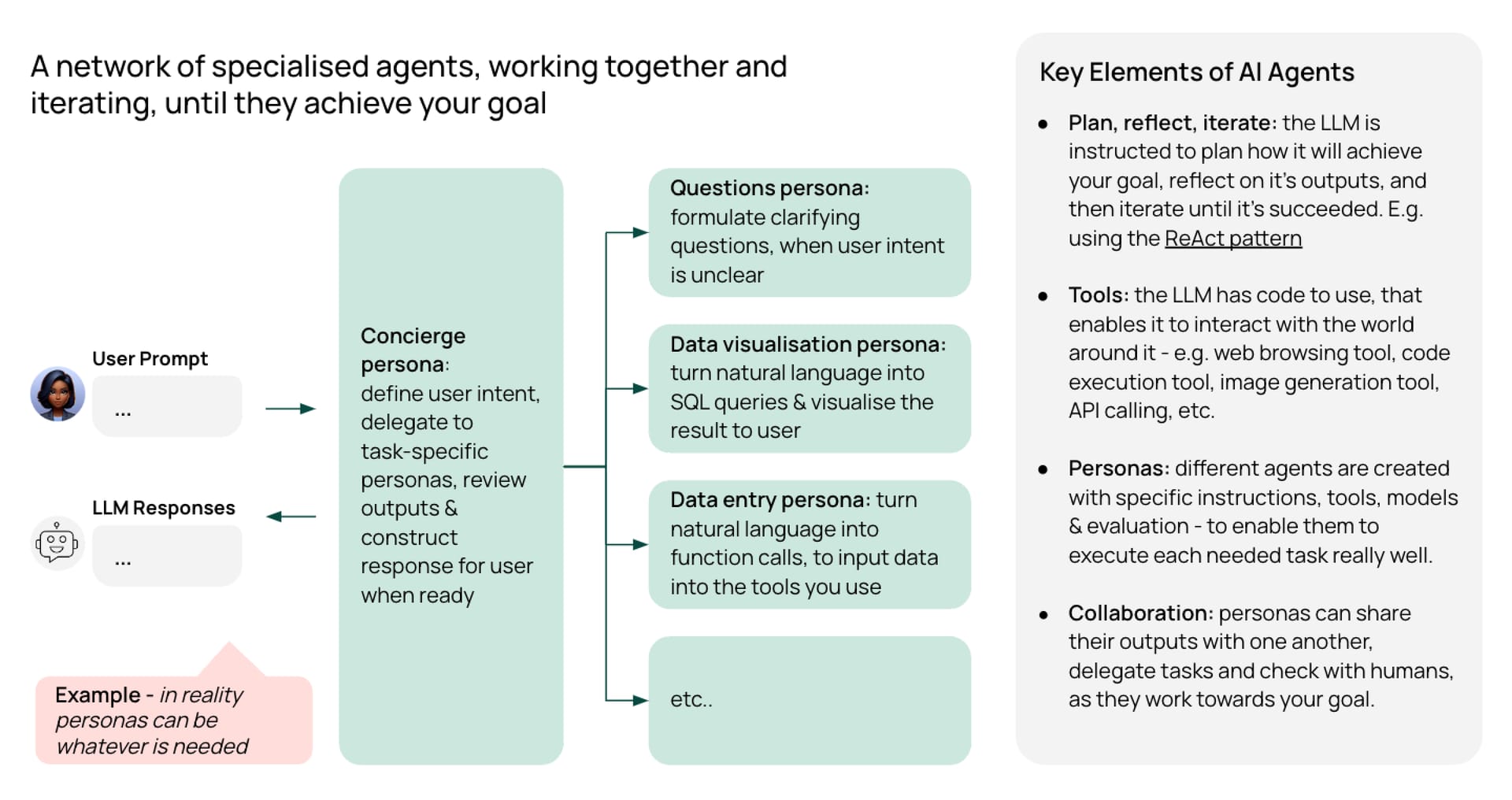
To continue the example, imagine you wanted to run an analysis on the data your first agent collected and then write a report about it. Once your ‘data collection agent’ has found the data, they could hand it over to your ‘analysis agent,’ who could then hand it over to your ‘report writing agent’ once the calculations are done. All while you sit and twiddle your thumbs.
Even though it’s early days, it’s clear agents will dramatically expand what LLMs can do. This test showed that GPT-3.5 outperforms GPT-4 when agent-based approaches are used vs. simple prompting. While this is just one benchmark, it supports what we’ve been learning first-hand in our projects, too.
The role of traditional machine learning alongside generative AI
Finally, it’s important to highlight that gen AI is just one more (very shiny) tool to add to the broader data science toolbox. It expands what we can do and how fast we can do it, but it doesn’t make ‘traditional’ machine learning tools redundant by any means.
In all our production projects, we’re using a combination of LLMs and ML – including things like clustering, classification & OCR. The ML approaches can be better, faster, more scalable, and cheaper for certain tasks.
Beyond the tech: A full-stack approach to custom AI solutions
Of course, the technologies are only one part of building successful custom solutions. To get real impact from AI, we need a problem worth solving where AI is truly the right tool for the job. Then we almost always need to change the ways of working, processes, roles, and mindsets - sometimes even operating and business models. We call this a full-stack approach.
You can read more about this in our gen AI working paper. This blog post is the second in a series that revisits its key learnings, with a few updates thrown in. You can find the first one here. Please get in touch if you'd like to discuss further!
 Jack RichardsonHead of Data & AI Transformation
Jack RichardsonHead of Data & AI Transformation




